The previous project proved a scratch CNN caps at ~81% on CIFAR-10 (10 classes). Here, ResNet18 pretrained on ImageNet classifies 100 sports at 93%+ by training only 0.5% of its parameters — and 96-98% after fine-tuning. Transfer learning doesn't just improve accuracy; it changes what's possible.
Two-Phase Approach
Architecture: ResNet18 → SportsClassifier
Blue = frozen in v1 | Green = always trainable | v2 unfreezes everything
Dataset: 100 Sports Classification
| Split | Images | Per Class | Purpose |
|---|---|---|---|
| Train | 13,493 | ~135 | Model training |
| Validation | 500 | 5 | Early stopping & LR decisions |
| Test | 500 | 5 | Final evaluation (never seen during training) |
Proper 3-way split — validation guides training decisions, test measures true generalization. This is the first project using a validation set separately from the test set.
Training Results
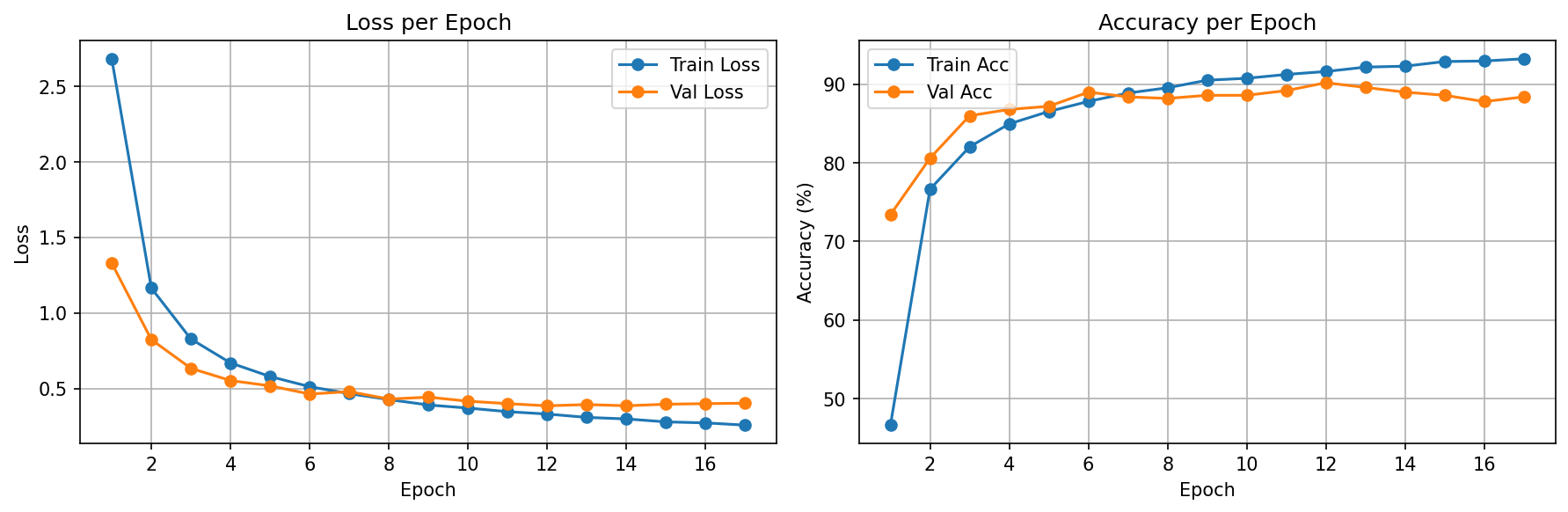
v1 — Feature Extraction
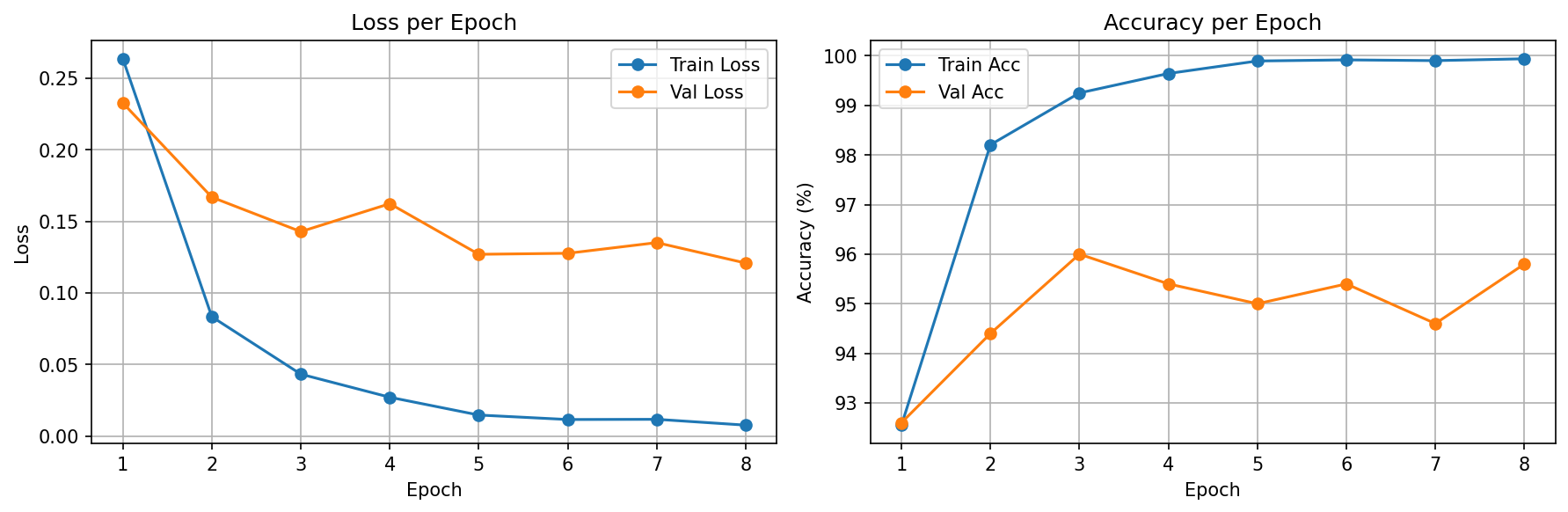
v2 — Fine-Tuning
Training Configuration Comparison
| Parameter | v1 (Feature Extraction) | v2 (Fine-Tuning) |
|---|---|---|
| Learning Rate | 0.001 | 0.0001 (10x smaller) |
| Trainable Params | 51,300 (FC only) | 11.2M (all layers) |
| Optimizer | Adam | Adam |
| Starting Weights | ImageNet pretrained | v1 best checkpoint |
| Early Stopping | patience=5 | patience=5 |
| Augmentation | RandomHorizontalFlip + RandomCrop(224, pad=8) + ImageNet normalization | |
Concepts Study Guide
Transfer Learning
Instead of training a model from random weights, you start with a model already trained on a large dataset (like ImageNet's 1.2M images, 1000 classes). The early layers have already learned universal visual features (edges, textures, shapes) that transfer to almost any image task. You only need to adapt the final layers to your specific problem.
Imagine learning to play tennis after years of badminton. You don't start from scratch — your hand-eye coordination, footwork, and court sense all transfer. You just need to adapt to the heavier racket and different ball physics. Transfer learning works the same way: the "visual coordination" learned on ImageNet transfers to sports classification.
When transfer learning works best:
• Your dataset is small (ours: 13K images vs ImageNet's 1.2M)
• Your task is similar to what the pretrained model learned (both are image classification)
• You don't have the compute resources to train a deep network from scratch
Transfer learning on Sports (100 classes): 93-98%
More classes, harder task, WAY better results. That's the power of transfer.
The previous project proved that a scratch CNN caps at ~81%. Transfer learning shatters this ceiling by leveraging features from a 11M-parameter network pretrained on millions of images. It's how the industry builds real image classifiers — almost nobody trains from scratch anymore.
Feature Extraction vs Fine-Tuning
Feature Extraction (v1): Freeze the entire pretrained backbone. Only train the new classification head (FC layer). The backbone acts as a fixed feature extractor — like plugging in a camera that already knows how to see.
Fine-Tuning (v2): Start from the feature extraction checkpoint, then unfreeze all layers and train everything with a much smaller learning rate. This lets the backbone adapt its features specifically to your task.
Feature extraction is like hiring an experienced photographer (pretrained backbone) and only teaching them what your company considers a "good photo" (new FC head). The photographer's skills are fixed.
Fine-tuning is like letting that photographer adjust their techniques specifically for your industry — they subtly change how they frame shots, handle lighting, etc. The foundation stays, but everything gets slightly customized.
Always do v1 first, then v2. Fine-tuning from random weights would destroy the pretrained features. Feature extraction gives the head a stable starting point, then fine-tuning refines the whole model gently.
We follow the standard 2-phase recipe: v1 establishes 93% with minimal training (only 51K params), then v2 pushes to 96.6% by letting the backbone adapt to sports-specific visual features. This progression demonstrates why both phases exist.
ResNet & Skip Connections
Deeper networks should be more powerful, but in practice, networks deeper than ~20 layers started performing worse due to the degradation problem — gradients vanish or explode through too many layers. ResNet solves this with skip (residual) connections: instead of learning output = F(x), each block learns output = F(x) + x. The + x shortcut lets gradients bypass layers entirely.
Imagine a 20-floor building with only stairs (regular deep network). Getting from floor 1 to 20 is exhausting, and messages (gradients) between floors get garbled. ResNet adds an elevator (skip connection) alongside the stairs. Important signals can take the elevator directly while each floor still does its processing. The result: even 100-floor buildings work perfectly.
Residual block: output = F(x) + x ← if F learns nothing, output = x (identity)
The "worst case" for a residual block is passing input through unchanged.
This makes it safe to stack many layers — useless layers do no harm.
ResNet-18 has 18 layers organized into 4 groups of BasicBlocks, each containing 2 conv layers with a skip connection. It was the 2015 ImageNet winner and remains a standard baseline.
We use ResNet18 as our pretrained backbone. Its skip connections are why it can be 18 layers deep without suffering from vanishing gradients — the exact problem that limited our 3-layer CIFAR-10 CNN. The architecture is the backbone; transfer learning is the strategy.
Catastrophic Forgetting
If you fine-tune a pretrained model with a learning rate that's too large, the gradient updates overwhelm the carefully learned weights. The model "forgets" the useful features from ImageNet and effectively becomes a randomly initialized network. The pretrained knowledge is lost.
Imagine an experienced surgeon retraining to specialize in a new procedure. With gentle, focused practice (small LR), they adapt their existing skills. But if you threw them into a boot camp that completely overrides everything they know (large LR), they'd lose their foundational skills and perform worse than a new student. That's catastrophic forgetting.
v2 (fine-tuning) LR: 0.0001 ← 10x smaller to protect backbone
Rule of thumb: fine-tuning LR should be 3-10x smaller than training LR
We used lr=0.0001 for fine-tuning (v2) vs lr=0.001 for feature extraction (v1). This 10x reduction ensures the backbone's ImageNet features are gently adapted, not destroyed. It's one of the most important practical details in transfer learning.
Train / Validation / Test Split
Training set: Used to update model weights (the model learns from this).
Validation set: Used to make decisions during training — early stopping, LR scheduling, hyperparameter tuning. The model never trains on this data, but your decisions are influenced by it.
Test set: Touched ONLY once, at the very end, to get the final unbiased performance estimate. No decisions are made based on test results.
Training set = homework problems (you learn from these).
Validation set = practice exams (you use these to decide if you're ready, adjust study strategy).
Test set = the final exam (seen exactly once, determines your actual grade).
If you peek at the final exam while studying, your grade is no longer a fair measure of what you know. That's data leakage.
This project: train (13,493) / val (500) / test (500)
Validation guides: early stopping patience, LR scheduling
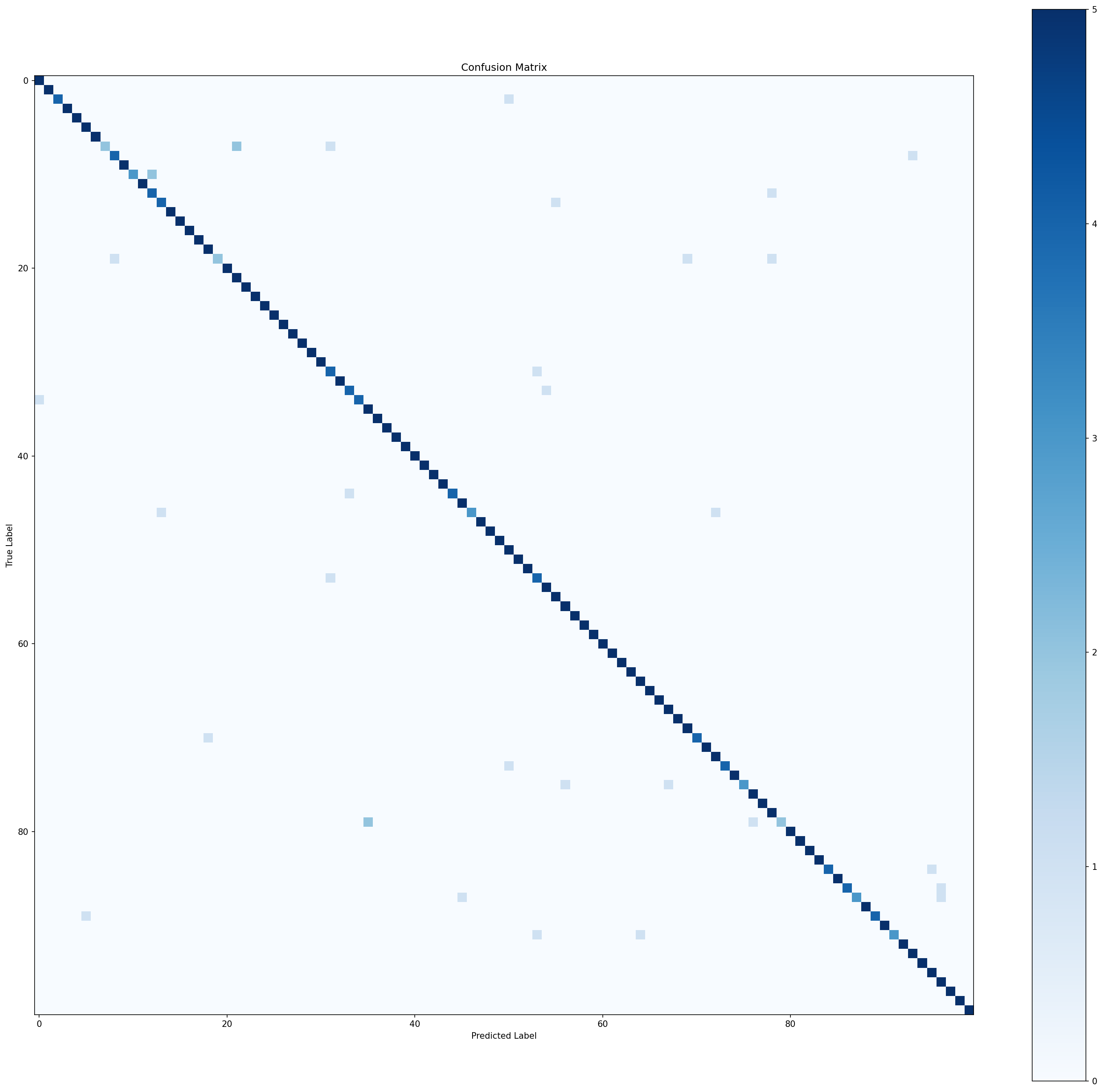
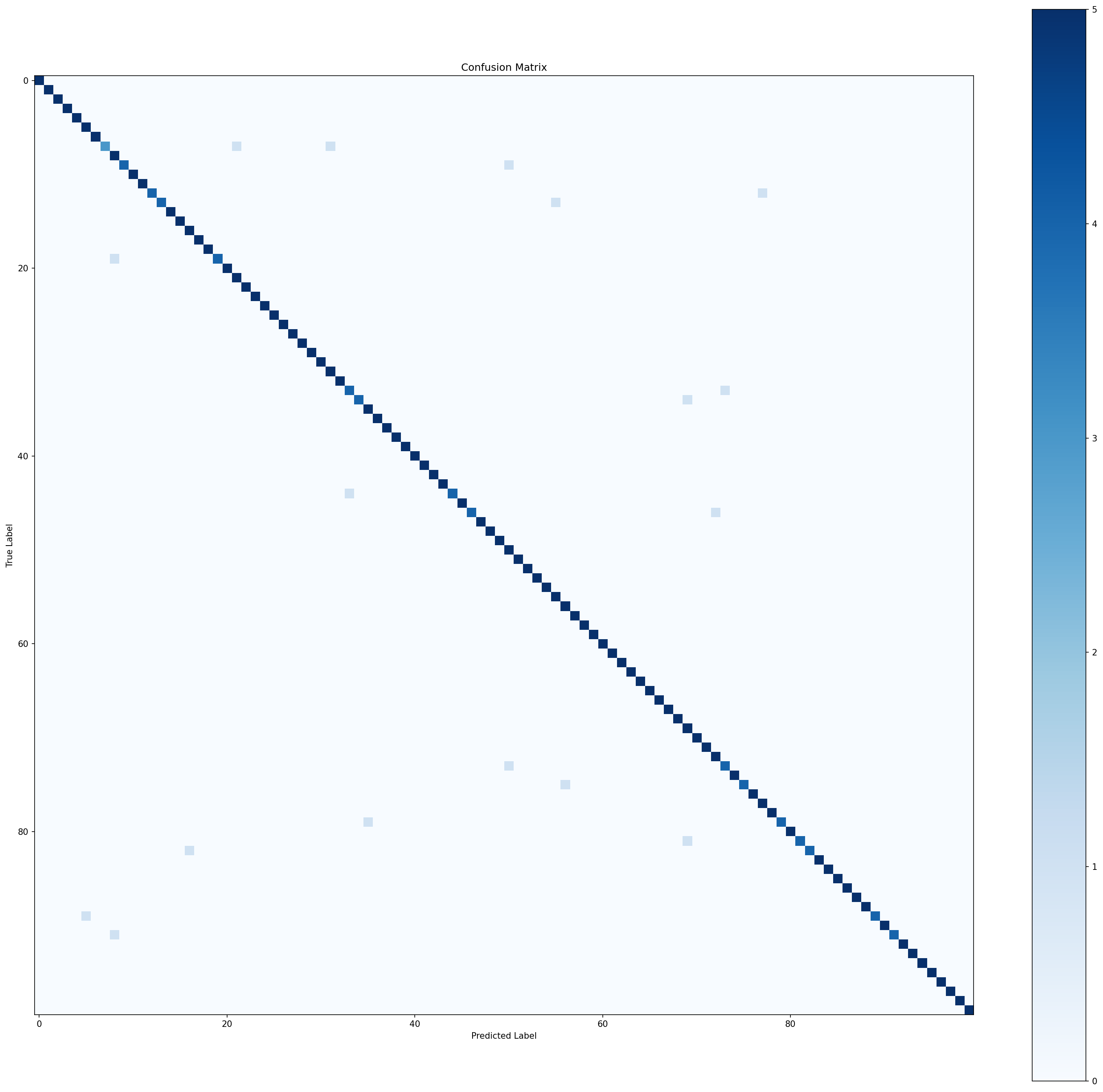
Test measures: true generalization (96.6% final answer)
This is the first project with a proper 3-way split. In previous projects, the test set influenced early stopping decisions (a mild form of data leakage). Here, validation and test are separate — the industry standard for any serious model evaluation.
ImageNet Normalization
Pretrained models expect inputs normalized with ImageNet's statistics: mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]. Using different normalization means the pixel values land in unexpected ranges, making all the pretrained features meaningless.
Imagine a translator trained on formal English. If you feed them text in internet slang, they'll produce nonsense — not because they're bad at translating, but because the input format doesn't match what they learned. ImageNet normalization ensures your images "speak the same language" as the training data.
mean=[0.485, 0.456, 0.406], # ImageNet RGB means
std=[0.229, 0.224, 0.225] # ImageNet RGB stds
)
Applied to ALL splits: train, val, and test (this is preprocessing, not augmentation)
Our ResNet18 was pretrained on ImageNet. Every pixel value must be normalized with ImageNet's statistics before feeding into the model. Forgetting this would silently produce garbage predictions without any obvious error — one of the most common transfer learning bugs.
Lessons Learned
optim.Adam(model.resnet.fc.parameters()), not model.parameters(). Passing frozen params wastes memory on optimizer states that will never be used.The Journey So Far
| Project | Task | Accuracy | Key Insight |
|---|---|---|---|
| 1. MNIST CNN | 10 digits | 99.35% | Learned the fundamentals |
| 2. CIFAR-10 CNN | 10 objects | 81.04% | Hit the scratch ceiling |
| 3. Transfer Learning | 100 sports | 96.60% | Pretrained features shatter the ceiling |
The narrative: harder tasks + better techniques = better results. Each project motivates the next.